生成秘钥公钥
1 | $ ssh-keygen //生成秘钥 |
客户端使用秘钥登录
1 | 1. /root/.ssh/id_rsa 到Windwos桌面 更改为.pem文件 |
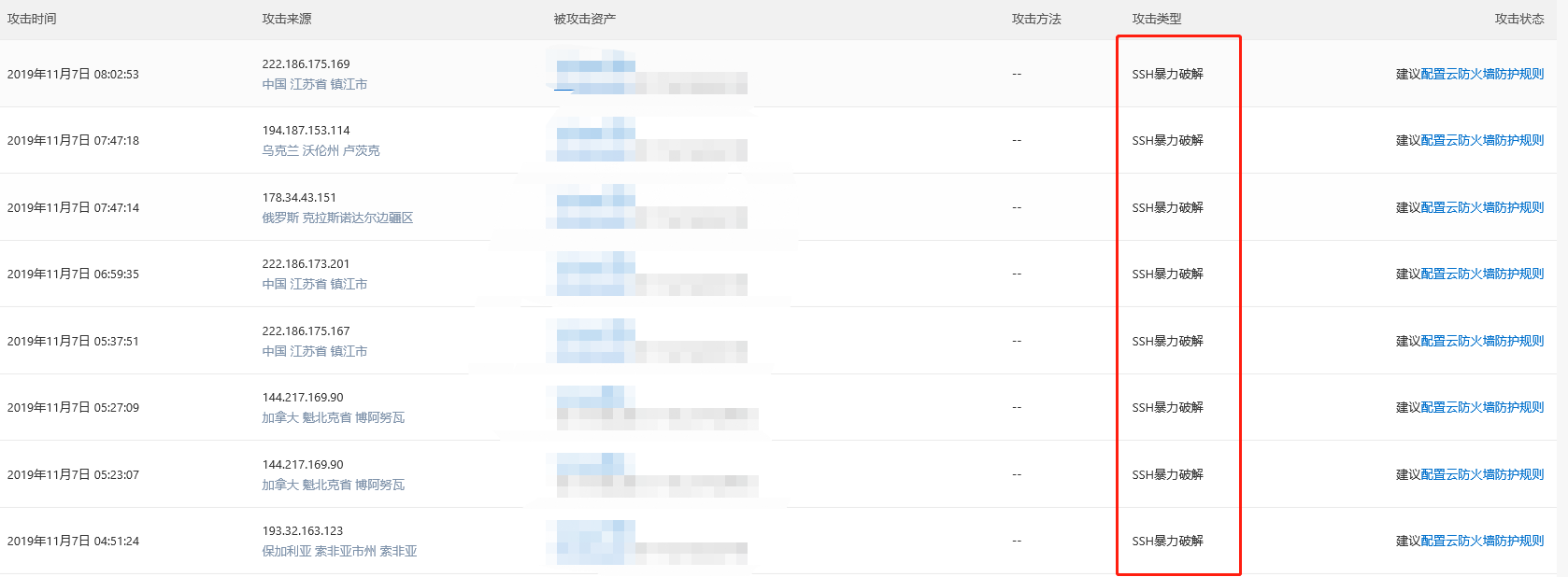
服务器被攻击如图
1 | $ ssh-keygen //生成秘钥 |
1 | 1. /root/.ssh/id_rsa 到Windwos桌面 更改为.pem文件 |
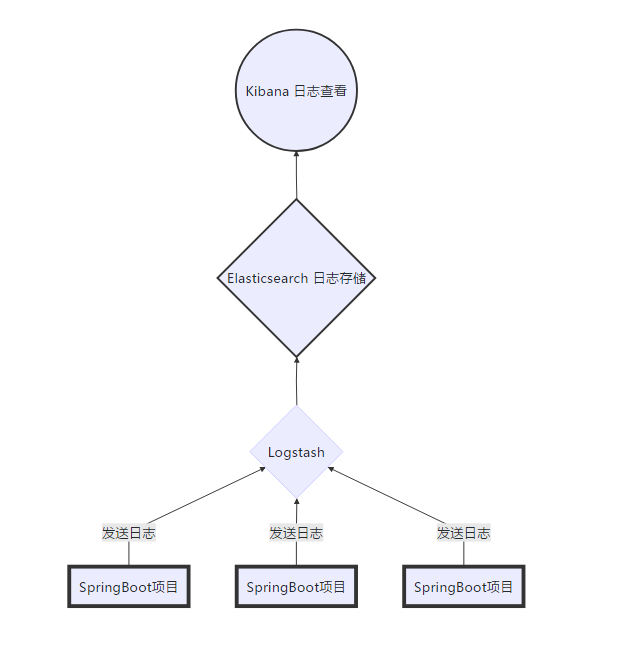
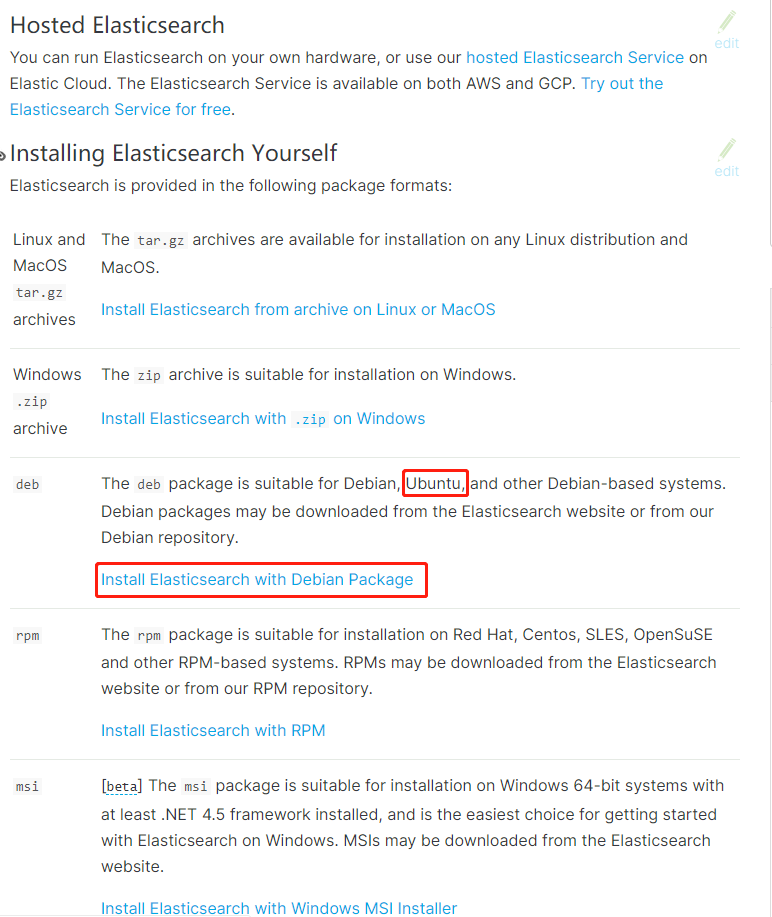
1 |
|
1 | #集群名称 |
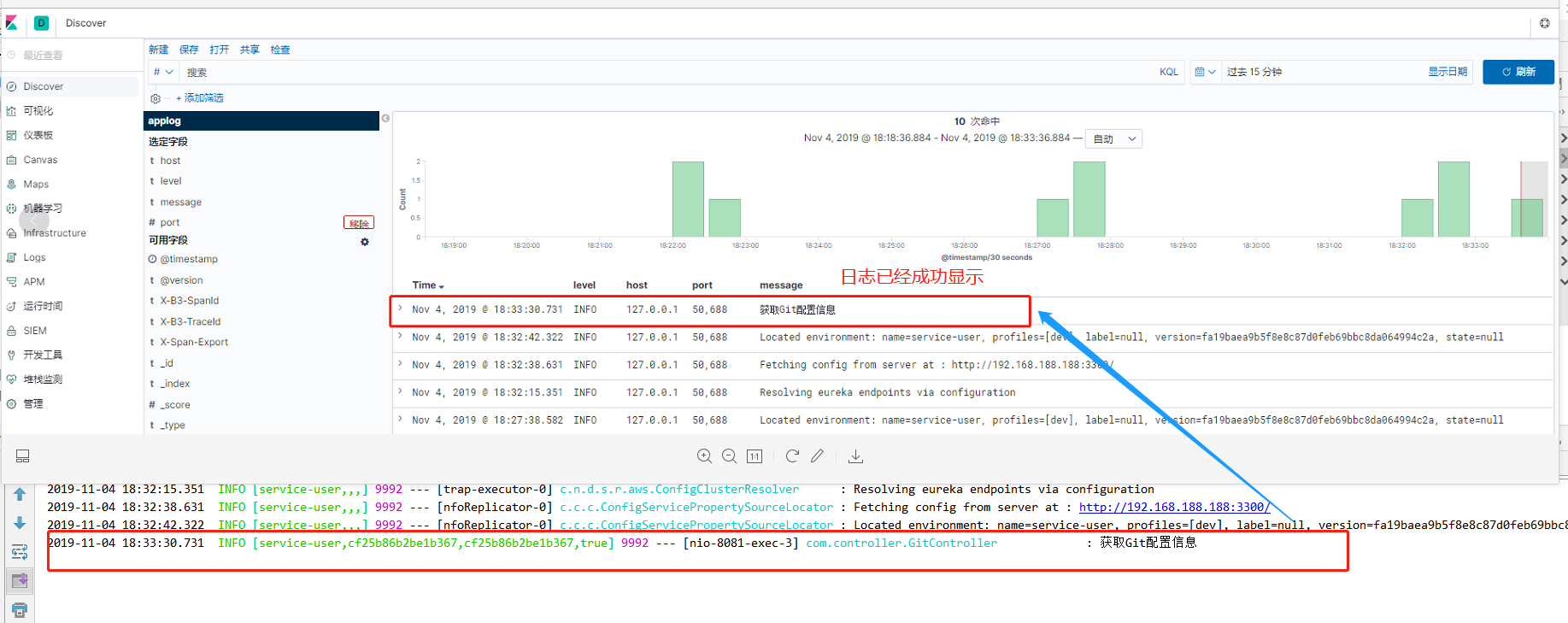
1 | ### Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。 |
1 | $ mkdir /es/logstash |
1 | $ curl cip.cc # 查看公网IP |
1 | $ vim /etc/ssh/sshd_config //编辑ssh的配置文件默认 /etc/ssh/sshd_config,在文件最后面另起一行添加 |
1 | $ vim /etc/ssh/sshd_config //找到#Port 22字段 删掉#,将22改为其他不被使用的端口 |
1 | $ find / -name *sync-huobi* |
1 |
|
1 | redis-cli -h IP -p 6379 -a password --bigkeys |
1 | nohup java -jar exchange-announcement-0.0.1-SNAPSHOT.jar > /home/logs/xxx.log & //后台启动一个Jar包 输出日志到指定文件 |
1 | pip install uncompyle 安装反编译工具 反编译python |
1 | $ mount /dev/vdb1 /clouddisk ##将云盘进行挂载 |
1 | $ %s#abc#123#g abc 替换为 123 //命令行 |